LCA data structure matters more than most teams realize
LCA data structure sounds technical, but it is the foundation for everything you want to do with LCA: dashboards, graphs, machine learning and tools that help people work with the data. If the structure is vague or inconsistent, all of that becomes slow, fragile and hard to scale.
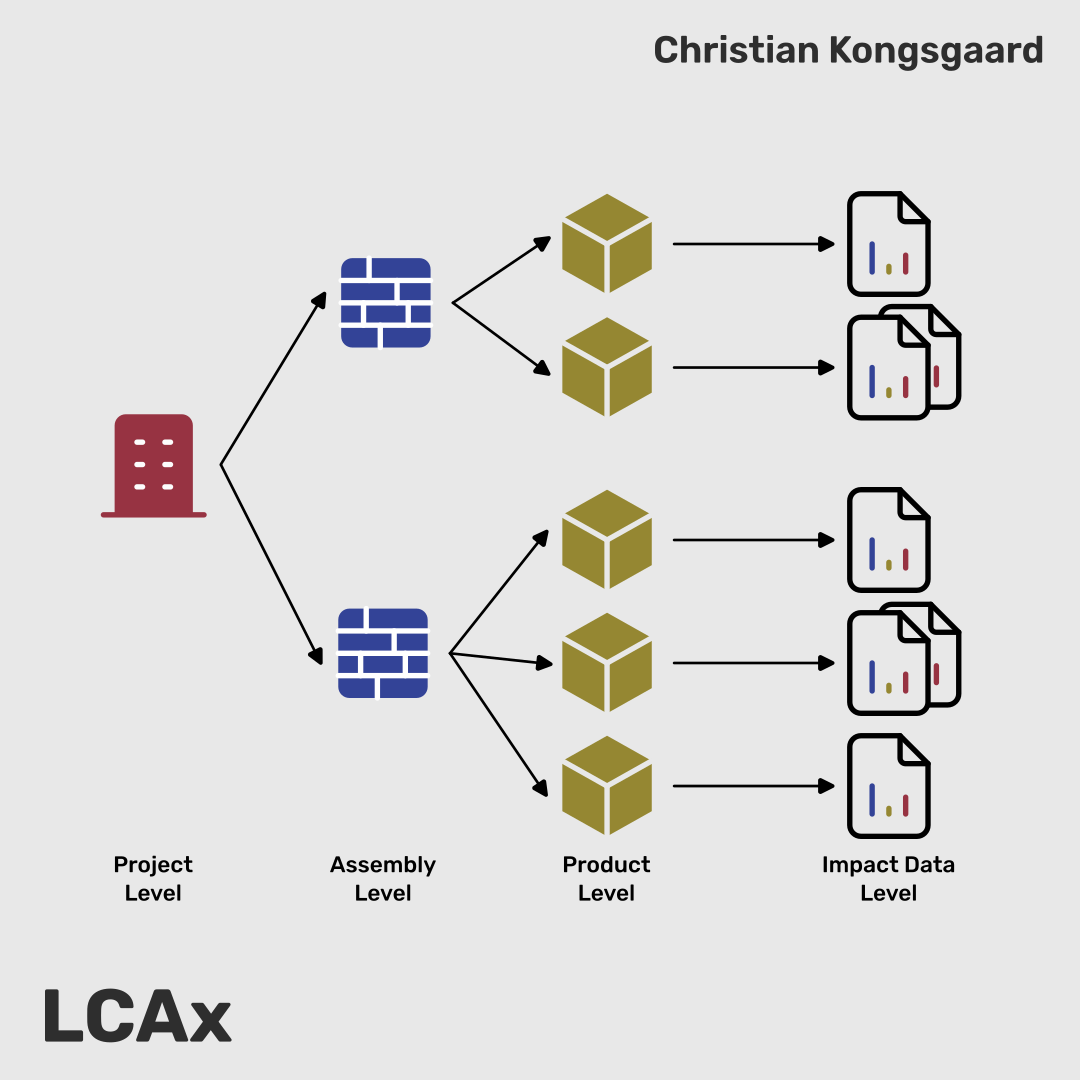
In LCAx, LCA data is organised in four simple levels that mirror a building. At the top is the project level with the basic context: project name, location, top level resources and what lifecycle modules or input categories are included in the calculations.
Inside the project are assemblies. These are the building components or buildups. Think of a wall. That wall assembly is built from multiple products: the brick layer, the insulation, the interior cladding and so on. Each of these is a separate product in the structure.
The fourth level is impact data. This is where the emission data lives and where you assign EPDs to products. Put together, the hierarchy matches how a building model is already structured, but with enough room for modification and flexibility to support many different LCA tools.
Today, many organisations still work in custom spreadsheets or tool specific formats. That makes it hard to reuse data or connect tools without manual fixes. One of the key advantages of LCAx’s infrastructure is that it uses an open and well defined format that anyone can read.
Used as a common standard for LCA, this structure makes analysis simpler, tool building easier and data exchange between LCA software much more realistic.
Best,
Christian